데이터베이스 인덱스의 구조에는 정렬된 값 목록이 포함되며, 각 값은 해당 값이 있는 데이터 페이지로 연결되는 포인터에 연결된다.
인덱스는 일반적으로 디스크에 저장된다. 데이터 검색 속도를 높이기 위해 테이블과 연결된다.
테이블의 하나 이상의 열에서 만들어진 키는 인덱스를 구성하며 대부분 관계형 데이터베이스의 경우 B+트리 구조에 저장된다.
데이터베이스에 적합한 인덱스를 차즌ㄴ 것은 빠른 쿼리 응답과 업데이트 비용 간의 균형을 맞추는 작업이다.
좁은 인덱스, 적은 인덱스는 디스크 공간과 유지 관리 비용을 절약한다.
넓은 인덱스는 더 넓은 범위 쿼리에 적합하다.
가장 효율적인 인덱스를 찾으려면 설계를 여러 번 반복해야 하는 경우가 많다.
B+Tree 입문
B+Tree는 특정 유형의 트리 데이터 구조이며 이를 이해하려면 이전 버전인 B-Tree에 대한 배경 지식이 필요하다.
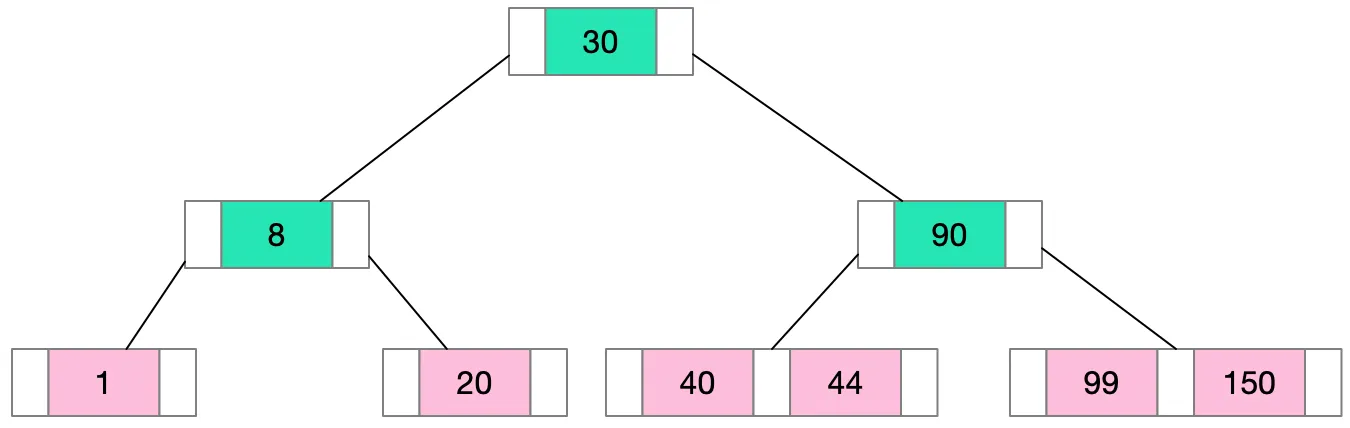
B-Tree는 다음과 같다.
모든 리프는 같은 높이에 있다. 이것으로 트리는 균형 잡힌 상태로 만든다.
루트를 제외한 모든 내부 노드에는 d(트리의 최소 차수)에서 2d까지의 자식 수가 있다. 그러나 루트에는 최소 2개의 자식이 있다.
자식이 k인 비리프 노드는 k-1개의 키를 포함한다. 즉, 노드에 3개의 자식이 있는 경우(k=3) 각 자식의 노드에 해당하는 세 부분으로 데이터를 분할하는 두 개의 키(k-1)를 보유한다.
B-Tree는 디스크 접근 횟수를 최소화하도록 설계되었기 때문에 메인 메모리에 맞지 않는 데이터를 저장하는데 탁월한 데이터 구조이다.
트리가 균형을 이루고 모든 리프 노드가 동일한 깊이에 있기 때문에 조회 시간은 일관되고 예측이 가능하다.
B+Tree는 B-Tree의 변형으로 디스크 기반 스토리지 시스템, 데이터베이스 인덱스에 널리 사용한다.
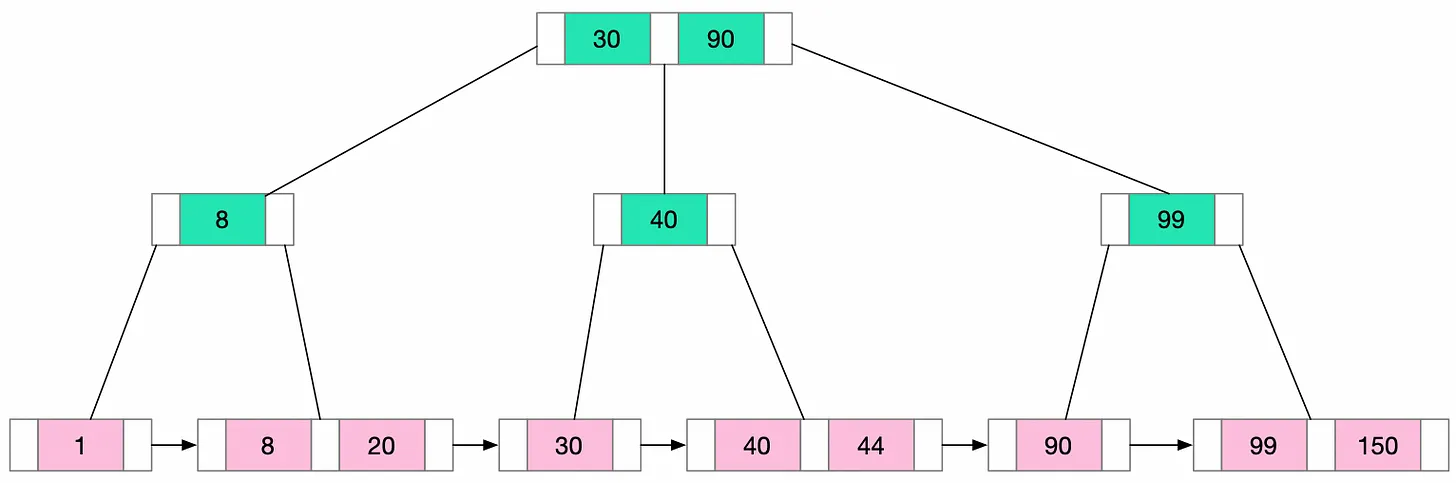
B+Tree에서 데이터 포인트는 리프 노드에만 저장된다. 내부 노드에는 다른 노드에 대한 키와 포인터만 포함된다. 이는 내부 노드에 더 많은 키를 저장할 수 있어 트리의 전체 높이가 줄어들 수 있음을 의미한다. 이렇게 하면 많은 작업에 필요한 디스크 엑세스 수가 줄어든다.
모든 리프 노드는 연결 리스트와 함께 연결된다. 이는 범위 쿼리를 효율적으로 만든다. 범위의 첫 번째 노드에 액세스한 다음 연결 목록을 따라가면 나머지 노드를 검색할 수 있다.
B+Tree에서 모든 키는 두 번 나타난다. 한 번은 내부 노드에, 한 번은 리프 노드에 나타난다. 내부 노드의 키는 원하는 값이 어느 하위 트리에 포함될 수 있는지 결정하기 위한 분할 지점 역할을 한다.
B+Tree는 위 기능으로 메인 메모리에 맞지 않은 대용량 데이터가 있는 시스템에 특히 적합하다. 데이터는 리프 노드에서만 액세스할 수 있으므로 모든 조회에는 루트에서 리프까지의 경로 탐색이 필요하다. 모든 데이터 엑세스 작업에는 일정한 시간이 걸린다. 이러한 예측 가능성으로 인해 B+Tree는 데이터베이스 인덱싱을 위한 매력적인 선택이 된다.